
Why Text-to-SQL is Failing for Agents and How to Fix It?
A proposed solution for a zero inaccuracy data retrieval for Agents


For those who have been in the tech and software industry long enough, you probably remember when information was organized with countless papers, files, cabinets and towering bookshelves in vast libraries.
In this analog world, retrieving information was mostly a tactile physical endeavor and often involved a conversation with a knowledgeable librarian or a meticulous search through a card catalog.
Then came the digital revolution, and a similar pattern of organizing information emerged, this time within computers with structured rows and columns of data organized in neat tables and schemas. We called these digital libraries, databases, a veritable dream come true for any self-respecting and consummate digital librarian with OCD.
But humans still needed to retrieve or query this massive amount of data, so a new language emerged that looked like shorthand for English -“Give me the name and age of all the people in my table called Users where the user age is between 31 and 50” became “SELECT NAME, AGE FROM USERS WHERE AGE BETWEEN 31 AND 50.” (Stay with me if you spotted a discrepancy in this “SQL” query. The nuanced inaccuracy is the point of this article.)
This became the de facto lingua franca for humans querying databases that we all now know today as — Structured Query Language or SQL for short. Over time, when more apps started to query databases than humans we saw the birth of NoSQL as a new way of organizing and “talking” to databases (the details for that story is best left for another day).
Today, however, we find ourselves in the midst of yet another larger and more consequential revolution with AI and Agents. Let me save you the history lesson from the last two years but now we are squarely headed into a world where Agents (with Large Language Models — LLMs as the underlying layer) querying database will far outpace any number of queries and traffic to the databases we ever seen either by humans or by applications.
SQL or NoSQL, is no longer adequate for the world of AI Agents.
In the last couple of years since the advent of LLMs, we have been feverishly trying to make the models convert NLP to SQL but the accuracy is woeful to say the least. Yes, the models will continue to get better but I don’t believe we will ever get to 100% accuracy, especially in organizations where it has taken years of trial and error with tribal knowledge to build 16-page-long SQLs to retrieve data in highly nuanced ways.
While we’ve relied on LLMs to bridge the gap between natural language and SQL, the inherent complexity of SQL, coupled with schema variations and database dialects, presents a significant bottleneck for scalable, AI-driven business solutions.
I don’t believe that in the current form, SQL will be the only and the primary way for LLMs to interact with databases.
What’s needed now is an evolution of SQL — a language purpose-built for Agents that prioritizes efficiency, speed, and reliability. This isn’t about replacing SQL entirely but introducing a complementary language that serves as the new lingua franca for intelligent systems.
In this article, let’s explore a new way to empower Agents to talk to databases with the primary goal of Zero tolerance (we will not look at vectors and semantic search in this blog) towards inaccuracies. Hence, the tongue-in-cheek reference to 0QL or ZeroQL.
If you are looking for tl:dr for the proposal, it is this — we will be exploring a new grammar-based Domain-Specific Language (DSL) exposed via a binary gRPC interface for all databases specifically built for AI Agents.
This idea is still a work in progress, but I’ve been reflecting on its potential for the last few weeks. I am going to share the rationale, design goals, and a blueprint for implementing a DSL layer. If you work in the world of databases and/or AI Agents and this resonates with you, then let’s collaborate and push these concepts forward together.
Let’s dive in.
The Problem
As organizations begin to integrate LLM-based agents into their data pipelines (e.g., for automated analytics, AI-driven data exploration), the potential for inaccuracies in generated SQL queries from LLMs is a massive challenge, especially in certain industries like healthcare or financial services. Such inaccuracies can not only lead to erroneous results, but sometimes dangerous outcomes if the result is being used to make decisions and take actions.
In my opinion the challenge of inaccuracy largely arises from the inherent freedom and complexity of SQL. Since it is a language originally designed for human readability and expressive power rather than machine-generated consistency, even with few-shot prompting and chain-of-thought reasoning, LLMs may produce syntactically correct but semantically invalid queries, or queries poorly optimized for the underlying database engine. Furthermore, LLMs working on petabyte-scale data must issue queries in a way that prioritizes accuracy without sacrificing latency which still needs to be in the order of milliseconds. The latency issue becomes even more pronounced in distributed environments, where network and processing delays compound.
The proposal
Given that SQL cannot be simply ripped and replaced, the proposal is to introduce a grammar-based DSL that formalizes queries into a constrained, machine-friendly format. Exposed via a binary gRPC interface, this DSL provides a stable and extensible foundation. By design, it reduces ambiguity, facilitates semantic validation, and potentially outperforms raw SQL generation scenarios. In an ideal world, this can be seen as a standardized intermediate layer — one that vendors and open-source projects (one can always dream or be delusion) can adopt to interface multiple databases with LLM Agents reliably and efficiently. Furthermore, this layer has the potential to harmonize disparate database systems, simplifying the querying process across heterogeneous data sources.
By treating data sources as logical tables and adding specialized syntax for various data types and operations, the DSL can serve as a universal query language that can evolve over time. Let’s look at some design objectives next.
Design goals for the proposal
Accuracy (Zero Tolerance):
Every produced query must be semantically valid and produce correct results. The DSL grammar and semantic checks enforce structural correctness. [Based on hypothesis: Adding a DSL parser and semantic validator reduces the incidence of invalid queries to near-zero.]Low latency:
Parsing a constrained DSL grammar is intuitively faster than parsing complex SQL strings. Combined with binary serialization via Protobuf and low-overhead RPC calls, we aim for millisecond-level responses.Extensibility and vendor neutrality:
While starting with simple SELECT queries, the DSL should evolve to handle joins, complex filters, aggregates, and multi-source federation. The approach must be adaptable to various back-end databases, from single-node RDBMS to distributed SQL engines like SingleStore.Schema introspection and versioning:
The DSL layer can include introspection endpoints to help LLMs dynamically learn about available tables and fields. Versioned grammar definitions and stable gRPC interfaces ensure that changes can be introduced without breaking existing clients.
Proposed architecture
The ZeroSQL architecture consists of three main constructs based on the proposed flow — LLM (fine tuned or prompt engineered to make use of DSL) sends queries to DSL. The DSL layer first runs through parser and then does semantic check which is then passed to specific adapters to native database and finally the query is executed and the response sent back.
DSL Grammar definition
An Extended Backus–Naur Form (EBNF) grammar defines the constructs (SELECT, FROM, WHERE, ORDER BY, LIMIT), ensuring no ambiguity. For instance:
Query = “SELECT”, FieldList, “FROM”, TableRef, [WhereClause], [OrderByClause], [LimitClause] ;
FieldList = Field { “,” Field } ;
WhereClause = “WHERE”, Condition { “AND” Condition } ;
Condition = identifier, Comparator, Value ;
…2. gRPC interface
A query_service.proto defines the RPC service:
service QueryService {
rpc Execute (QueryRequest) returns (QueryResponse);
}3. Semantic Validation
Semantic validators check, for example, if the referenced table and columns exist (using the database’s INFORMATION_SCHEMA) and ensure compatibility of operators and data types. This step ensures the DSL query is not only syntactically but also semantically correct before hitting the database.
An actual use case
The idea of this abstract DSL layer came into being when I was talking to a Fortune 10 company that brought up the following use case while talking about advanced Retrieval Augmented Generation (RAG) to make LLMs “talk” to enterprise databases.
Imagine a massive database environment with hundreds and possibly thousands of entities around a company’s sales and revenue data. In this scenario, a “quarter” is not a universal concept; it depends on a company’s fiscal year definition, which might run from March to February instead of the standard calendar year.
Key problem in free-form SQL generation:
If an LLM attempts to answer the question of “how much sales did we have in the last quarter?” directly by generating SQL, it might choose the wrong table or make incorrect assumptions. For example, it could guess a table named sales and a date range for the quarter, but if it chooses January-March for Q1 when the company’s Q1 is actually March-May, the results will be incorrect. Similarly, it might reference a table sales_transactions when the actual data is in sales_fact or revenue_records.
How the DSL solves the problem:
Definition of “quarter”: The LLM uses schema introspection through the DSL to find the right dimension table that defines the fiscal quarter. This ensures semantic accuracy by deriving quarter boundaries from the authoritative source rather than guessing.
Right Table and Columns: The DSL introspection reveals the correct fact table (sales_fact) and the correct columns (sales_amount, sale_date). The LLM’s initial attempts may fail until it references only valid, known entities.
Zero tolerance for inaccuracies: Any incorrect reference or assumption is caught at the DSL validation stage, forcing the LLM to correct the query. This ensures that by the time the query runs, it is guaranteed to be semantically correct for the database in question.
This approach ensures that even in a massive, complex schema environment, the LLM cannot successfully produce an incorrect query. It must comply with the DSL constraints, validated schema references, and semantic rules, effectively guaranteeing “zero tolerance” for inaccuracies.
An example:
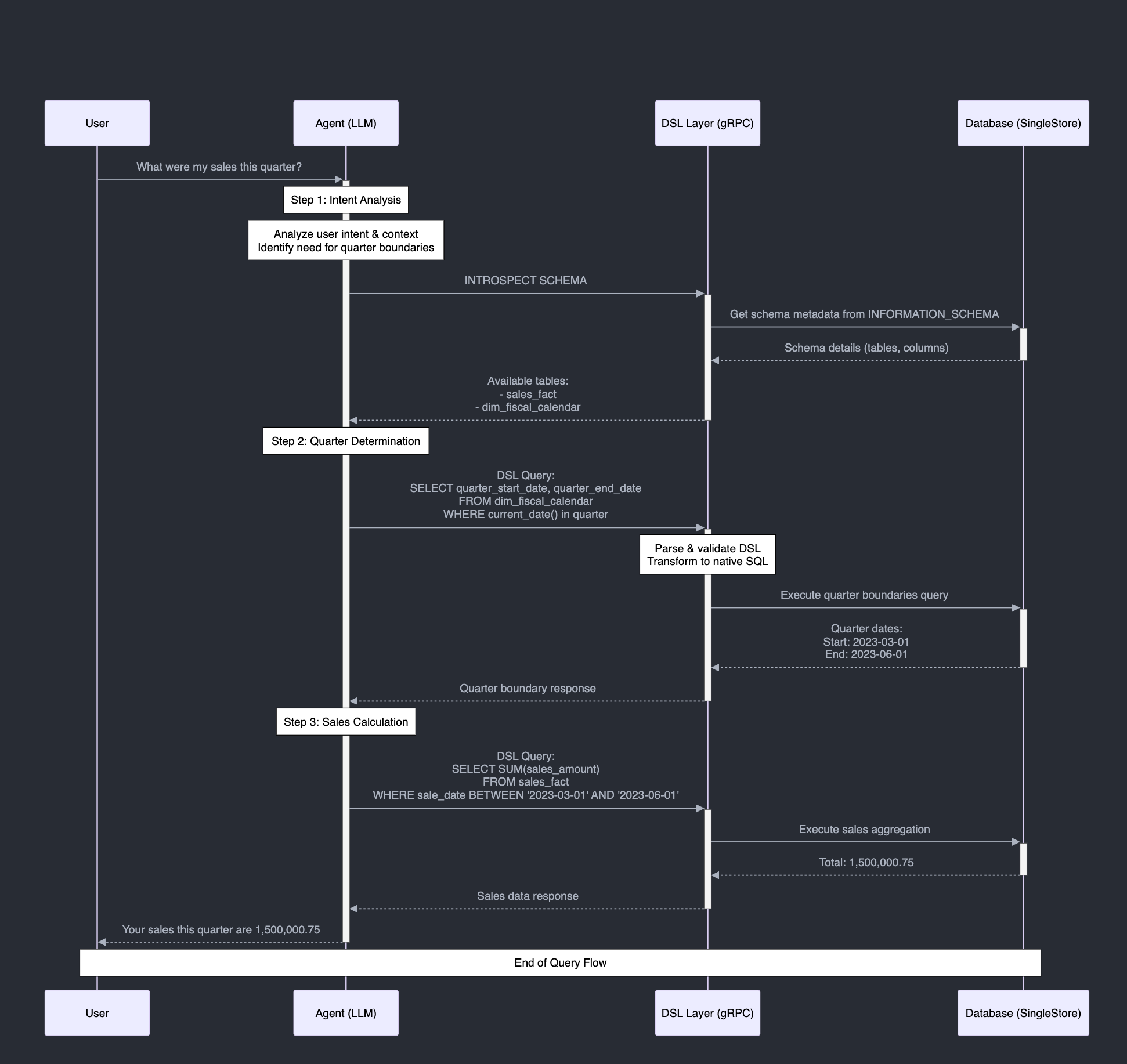
Initial natural language request:
The user asks, “What were my sales this quarter?” The LLM understands it needs to determine what “this quarter” means in the company’s fiscal definition.Schema introspection via DSL:
The LLM issues a DSL introspection request. The DSL service returns schema details so the LLM knows which tables are available (e.g., dim_fiscal_calendar for quarter boundaries).Finding the current fiscal quarter:
With schema info, the LLM sends a DSL query to find the current quarter’s start and end date from dim_fiscal_calendar. The DSL layer validates the query and translates it into a SQL statement that the database can execute.Fetching quarter boundaries:
The database returns the current quarter’s start and end dates, e.g., March 1 to June 1.Querying sales in that timeframe:
Now that the LLM knows the exact date range, it issues another DSL query to sum sales amounts from sales_fact within these dates. The DSL service again validates, translates, and executes the query on the database.Returning the result:
The database returns the aggregated sales figure. The DSL service sends the structured result back to the LLM, which then composes a final natural language answer for the user.
This sequence illustrates how the DSL and the gRPC interface ensure correctness and semantic accuracy (no referencing non-existent tables or misusing date ranges) while providing timely, accurate results from a complex database schema.
How is this different from SQL?
At first glance, the DSL queries may look superficially similar to SQL. However, if you notice, the difference lies not just in syntax, but in how the DSL is defined, validated, and enforced:
Restricted grammar and strict parsing:
The DSL is defined by a strict grammar that allows no ambiguity or vendor-specific quirks. In SQL, different dialects or versions can interpret certain constructs differently. The DSL is narrower and more uniform, which means every DSL query that passes the grammar check is known to follow a strict structure.Semantic validation and schema awareness:
The DSL layer is designed to integrate closely with schema metadata. Before a DSL query is accepted, the system checks:Are all referenced tables known and allowed?
Do all referenced columns exist in those tables?
Are the data types and operators compatible?
While SQL engines also do semantic checks, the DSL layer aims to catch and correct these issues before the query is even transformed into native SQL. If something is off, the DSL validator provides immediate, structured feedback that the LLM can use to correct the query.
Stable Interface for LLMs:
SQL is large and complex, and LLMs must handle the full flexibility and dialect variations. The DSL deliberately restricts this flexibility, making it easier for LLMs to generate valid queries consistently. This “machine speak” is less about allowing human creativity and more about providing a stable, machine-friendly language that an LLM can easily learn and not deviate from.Extensibility and controlled evolution:
Over time, developers/maintainers will add new features, operators, or syntax rules to the DSL. Because it’s all centrally defined and validated, introducing these changes is more controlled. LLMs can be updated or prompted with the new grammar. SQL dialect differences and random user-defined functions are minimized or standardized at this layer.
In short, the DSL is a constrained, validated, and stable subset or variant designed for programmatic generation and validation rather than the entire breadth of SQL’s flexibility and vendor-specific oddities.
To be fair this approach is not without its disadvantages so let’s weigh the pros and cons with the main goal of still maintaining a more deterministically accurate response.
Pros:
Higher accuracy:
A strict grammar and fewer degrees of freedom reduce the chance of malformed queries.Performance gains:
DSL parsing can be optimized. Combined with binary serialization and minimal overhead, this approach meets low-latency demands. One could also use parallelism to make this faster.Extensibility & portability:
Any database can integrate by writing an adapter. Changes to the DSL layer do not affect the LLM’s learned patterns significantly. This is based on the assumption that stable DSL reduces LLM retraining frequency.Unified interface:
Organizations with heterogeneous data systems can present a single DSL interface, simplifying training and prompting strategies.
Cons:
Initial complexity:
Developing a new DSL and maintaining its grammar requires engineering effort and consensus. I can see that quite possibly this only succeeds as an open source project backed by a large company with massive distribution channels.Learning curve for adapters:
Database vendors must implement an adapter layer. This introduces an integration burden, though once done, it simplifies future queries. I understand this is a big challenge but gets easier if a large database provider adapts this as a standard (similar to what happened with Apache Iceberg).Limited expressiveness initially:
A minimal DSL might not capture all SQL capabilities out-of-the-box. Ongoing refinement is needed to match the richness of SQL.
Conclusion
NLP to SQL is an intractable problem due to its complexity and ambiguity, leading to errors and inefficiencies that makes the solution unusable in enterprises. A possible solution to this could be to introduce a grammar-based Domain-Specific Language (DSL) with a gRPC interface, acting as a middle layer between LLMs and databases as I proposed in this article. This DSL prioritizes accuracy, speed, and extensibility, ensuring that AI agents can communicate with databases reliably and efficiently.
IMHO pretty soon the LLMs would have reached “super intelligence” but data access would still remain a problem unless we figure out possible solutions to make the databases efficient to interact with Agents. This article just covers one of them.
✌️